ELEKTRO INDONESIA Edisi ke Delapan, Juli 1997
Desain Chace pada Sistem Komputer
Sementara unjuk-kerja prosesor
bertambah tinggi dua kali lipat
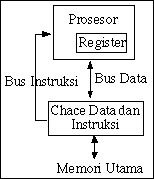
setiap 18-24 bulan, kecepatan akses data dari memori dinamik, yang biasanya dipasang sebagai memori utama, hanya bertambah cepat beberapa persen tiap tahun. Pada rancangan prosesor modern dengan beberapa tingkat pipeline, upaya untuk mengisi penuh seluruh pipeline dengan instruksi dan data perlu dilakukan agar operasi sistem komputer secara keseluruhan efisien. Perbedaan kecepatan operasi antara prosesor dan memori utama bisa menjadi kendala bagi dicapainya efisiensi kerja sistem komputer. Bila prosesor bekerja jauh lebih cepat daripada memori utama maka setiap kali prosesor mengambil instruksi atau data, diperlukan waktu tunggu yang cukup lama. Waktu tunggu tersebut akan lebih berarti bila digunakan untuk memproses data. Kendala ini menyebabkan diperlukannya cache, yakni memori berkapasitas kecil tetapi berkecepatan tinggi, yang dipasang di antara prosesor dan memori utama. Instruksi dan data yang sering diakses oleh prosesor ditempatkan dalam cache sehingga dapat lebih cepat diakses oleh prosesor. Hanya bila data atau instruksi yang diperlukan tidak tersedia dalam cache barulah prosesor mencarinya dalam memori utama.
Cache umumnya menggunakan memori statik yang mahal harganya, sedangkan memori utama menggunakan memori dinamik yang jauh lebih murah. Sistem komputer akan bekerja sangat cepat apabila seluruh sistem memori utamanya menggunakan memori statik, tetapi akibatnya harga sistem komputer akan menjadi sangat mahal. Selain itu, karena hamburan panas pada memori statik lebih besar, sistem komputer yang menggunakan memori statik ini akan menghasilkan panas yang berlebihan.
Hirarki Sistem Memori
Pada sistem komputer terdapat berbagai jenis memori, yang berdasarkan kecepatan dan posisi relatifnya terhadap prosesor, bisa disusun secara hirarkis seperti ditunjukkan pada  Gambar 1.
Gambar 1.
Puncak hirarki sistem "memori" komputer adalah register yang berada dalam cip prosesor dan merupakan bagian integral dari prosesor itu sendiri. Isi register-register itu bisa dibaca dan ditulisi dalam satu siklus detak. Level hirarki berikutnya adalah memori cache internal (on-chip). Kapasitas cache internal yang sering disebut sebagai cache level pertama ini umumnya sekitar 8 KB. Waktu yang diperlukan untuk mengakses data atau instruksi dalam cache internal ini sedikit lebih lama dibanding register, yakni beberapa siklus detak. Prosesor-prosesor mutakhir dilengkapi dengan cache level kedua yang kapasitasnya lebih besar dan ditempatkan di luar cip. Prosesor P6 (Pentium Pro), misalnya, cache level pertamanya berkapasitas 8KB untuk data dan 8 KB untuk instruksi. Cache level keduanya berkapasitas 256 KB, yang merupakan keping terpisah tetapi dikemas menjadi satu dengan pro- sesornya (Halfhill, 1995:42).
Selama program dieksekusi, sistem komputer secara terus menerus memindah-mindahkan data dan instruksi ke berbagai tingkat dalam hirarki sistem "memori". Data dipindahkan menuju ke puncak hirarki bila diakses oleh prosesor, dan dikembalikan lagi ke hirarki yang lebih rendah bila sudah tidak diperlukan lagi. Data-data tersebut ditransfer dalam satuan-satuan yang disebut "blok"; satu "blok" dalam cache disebut satu "baris". Umumnya, data yang berada pada suatu level hirarki merupakan bagian dari data yang disimpan pada level di bawahnya.
Program komputer pada umumnya tidak mengakses memori secara acak. Besar kecenderungannya bahwa bila program mengakses suatu word maka dalam waktu dekat word tersebut akan diakses lagi. Hal ini dikenal sebagai prinsip lokalitas temporal. Juga besar kecenderungannya bahwa dalam waktu dekat word yang berada di dekat word yang baru diakses akan diakses juga. Yang terakhir ini dikenal sebagai prinsip lokalitas spatial. Karena sifat lokalitas temporal, maka harus diperhatikan word yang telah ada dalam cache, dan karena sifat lokalitas spatial maka perlu diperhatikan kemungkinan memindahkan beberapa word yang berdekatan sekaligus.
Rasio (Kena) dan Waktu Akses
Kemungkinan bahwa suatu kata (word) berupa data/instruksi ditemukan dalam cache (disebut kena atau hit) sehingga prosesor tidak perlu mencarinya dalam memori utama, akan tergantung pada program, ukuran dan organisasi cache. Bila kata yang diperlukan tidak ada dalam cache (berarti luput atau miss), maka prosesor harus merujuknya ke memori utama. Rasio kena (h) didefinisikan sebagai perbandingan antara jumlah perujukan yang berhasil memperoleh kata dari cache dengan banyaknya perujukan yang dilakukan.
h = (jumlah perujukan yang berhasil) / ( jumlah perujukan)
Dalam studi tentang cache, pengukuran umumnya justru terhadap rasio luput (miss) yang besarnya adalah:
m = (1 - h)
Waktu akses rata-rata, dengan asumsi bahwa perujukan selalu dilakukan ke cache lebih dahulu sebelum ke memori utama, dapat dihitung sebagai berikut:
t
a = t
c + (1-h) t
m
dengan ta adalah waktu akses rata-rata, t
c adalah waktu akses cache dan tm adalah waktu akses ke memori utama. Setiap kali prosesor terpaksa mengakses memori utama, diperlukan tambahan waktu akses sebesar t
m (1-h). Misalnya, bila rasio kena adalah 0,85, waktu akses ke memori utama adalah 200 ns dan waktu akses ke cache adalah 25 ns, maka waktu akses rata-rata adalah 55 ns.
Bila persamaan ta disusun ulang, dapat ditulis menjadi:
t
a
= t
c {1/k + (1-h)}
dengan k adalah rasio antara waktu akses memori utama dengan waktu akses cache (tm/tc).
Dari persamaan di atas dapat dilihat bahwa waktu akses rata-rata didominasi oleh rasio waktu akses memori utama dengan cache bila k kecil. Pada kasus di atas, dengan waktu akses memori utama 200 ns dan waktu akses cache 25 ns, maka k = 8. Rasio luput 1 prosen menyebabkan waktu akses rata-rata menjadi 27 ns, tidak jauh beda dengan waktu akses cache. Pada umumnya k berkisar antara 3-10 (Wilkinson, 1991:68).
Organisasi Cache
Dalam mendesain sistem cache, yang pertama kali perlu diperhatikan adalah masalah penempatan suatu blok data/instruksi dari memori utama ke baris-baris cache. Berkaitan dengan masalah itu, ada tiga macam organisasi cache yakni organisasi cache yang dipetakan langsung (direct-mapped), asosiatif penuh (fully associative), dan asosiatif-kelompok ( set-associative). Skema pada Gambar 2a, Gambar 2b, Gambar 2c, menunjukkan bagaimana ketiga organisasi cache itu bekerja (Bacon, 1994:79-81).
Misalkan suatu sistem menggunakan pengalamatan 32-bit. Jika ukuran tiap-tiap blok adalah 64 byte (26) maka 6-bit terendah dari alamat tersebut � yang disebut offset � menentukan byte mana dalam blok itu yang dialamati. Jika cache terdiri atas 1024 (210) baris yang masing-masing terdiri dari 64 byte, maka 10 bit berikutnya menentukan pada baris mana blok yang diambil harus ditempatkan. Bit sisanya, yakni 16-bit paling atas yang disebut tag bersesuaian dengan baris cache. Organisasi cache yang dipetakan langsung, menyimpan satu tag perbaris dalam larik tag-nya.
Selama pengaksesan memori, pada operasi load misalnya, cache menggunakan bit-bit tengah alamat sebagai indeks ke larik tagnya. Tag yang muncul dicocokkan dengan 16-bit teratas dari alamat memori yang diakses. Jika cocok, data yang ditunjukan oleh nilai offset akan dikirim ke prosesor. Bila tidak cocok, isi baris cache diganti dengan blok yang diperlukan, yang diambil dari memori utama.
Organisasi cache yang dipetakan langsung hanya memerlukan satu kali pembandingan untuk setiap akses ke cache. Baris cache merupakan indeks yang diimplementasikan dengan perangkat keras, sehingga hanya tag dari alamat memori yang diakses yang perlu dibandingkan dengan baris cache. Pada sistem komputer yang memerlukan frekuensi detak tinggi, cara ini sangat menguntungkan. Masalah muncul apabila dua blok yang sering diakses dipetakan ke baris cache yang sama. Dua blok ini akan saling usir dari cache.
Pada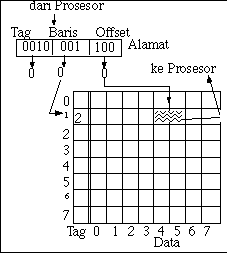 Gambar 2a terlihat bahwa bagian alamat yang membentuk tag tidak digunakan untuk memetakan alamat pada baris cache, sehingga bila alamat-alamat tersebut hanya berbeda bit tagnya, akan terjadi konflik.
Gambar 2a terlihat bahwa bagian alamat yang membentuk tag tidak digunakan untuk memetakan alamat pada baris cache, sehingga bila alamat-alamat tersebut hanya berbeda bit tagnya, akan terjadi konflik.
Alamat dibagi menjadi dua bagian, yakni bagian tag dan offset. Tag dicocokkan dengan seluruh tag yang ada dalam baris cache.
Dalam rancangan cache asosiatif-penuh (fully associative), suatu blok dapat ditempatkan pada baris cache manapun. Secara sederhana alamat dibagi menjadi dua bagian yakni bit rendah dan bit tinggi. Bit rendah membentuk offset di dalam baris cache, sedangkan bit tinggi membentuk tag untuk dicocokkan dengan rujukan berikutnya.
Cache asosiatif-penuh harus memiliki mekanisme untuk menentukan ke dalam baris mana suatu blok harus ditempatkan. Blok dapat ditempatkan dalam baris manapun yang kosong, tetapi bila semua baris cache penuh harus ditentukan blok mana yang akan dikeluarkan dari cache. Idealnya, digunakan prinsip LRU (least recently used) yakni blok yang paling lama tidak dipakai dikeluarkan dari cache. Karena cukup mahal mengimplementasikannya, maka umumnya digunakan teknik-teknik yang mendekati prinsip LRU.
Cache asosiatif-penuh memecahkan masalah konflik alamat dengan resiko memperbanyak implementasi rangkaian perangkat keras untuk membandingkan tag terhadap semua baris cache. Untuk memperkecil resiko tersebut sekaligus mengurangi terjadinya konflik alamat, dirancang organisasi cache yang lain yakni asosiatif-kelompok (set-associative).
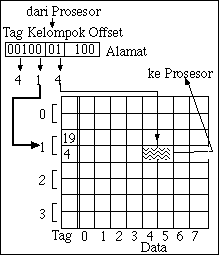
Dalam cache asosiatif-kelompok, satu kelompok terdiri atas beberapa baris. Bit alamat bagian tengah menentukan kelompok baris di mana suatu blok ditempatkan. Pada contoh Gambar 2c satu kelompok terdiri atas dua baris sehingga disebut sebagai organisasi asosiatif-kelompok dua-jalan (two-way set-associative). Mikroprosesor Amd486DX2, misalnya, memiliki 8 KB cache asosiatif-kelompok empat-jalan (four-way set-associative) dengan baris masing-masing selebar 26 byte. Cache sebesar 8 KB tersebut dibagi menjadi 128 kelompok yang masing-masing terdiri atas empat baris (AMD, 1993).
Dalam setiap kelompok, cache dipetakan secara asosiatif-penuh. Cache dengan dua baris per kelompok atau cache asosiatif-kelompok dua-jalan memerlukan dua pembandingan untuk satu kali akses. Selain membutuhkan lebih sedikit pembandingan dibanding cache asosiatif-penuh, cache asosiatif-kelompok juga memudahkan implementasi teknik LRU (least recently used).
Bit tengah dari alamat digunakan untuk memilih sekelompok baris (bukan hanya satu baris seperti pada sistem pemetaan langsung). Tag alamat kemudian dicocokkan dengan tag seluruh baris cache yang dipilih.
Selain ketiga organisasi cache di atas, pada masa-masa awal pemanfaatan sistem cache beberapa jenis prosesor menggunakan cache, dengan pemetaan-sektor. Pada pemetaan sektor, baik memori utama maupun cache dibagi menjadi sektor-sektor. Setiap sektor terdiri atas sejumlah blok. Sembarang sektor pada memori utama dapat terpetakan ke sembarang sektor dalam cache, dengan suatu tag disimpan bersama tiap-tiap sektor dalam cache untuk mengidentifikasi alamat sektor memori utama. Dalam pengirimannya ke cache atau pengembaliannya ke memori utama, data/instruksi tidak dikirim sektor per sektor tetapi blok per blok. Pada saat terjadi luput sektor (sector miss) blok yang diperlukan dari satu sektor dipindahkan ke lokasi tertentu dalam satu sektor. Lokasi sektor dalam cache dipilih berdasarkan algoritma penggantian tertentu. Desain ini sudah tidak populer lagi karena prosentase kena (hit) lebih rendah dibanting dengan organisasi asosiatif-kelompok (Wilkinson, 1991:74-75; Hwang dan Briggs, 1985:106-107).
Cache Tunggal dan Cache Ganda
Bagaimanapun baiknya organisasi cache, kemungkinan terjadinya luput (miss), yakni tidak didapatkannya instruksi atau data yang diperlukan di dalam cache sehingga prosesor harus mengaksesnya dari memori utama, selalu ada. Prosentase luput yang terjadi merupakan salah satu kriteria dalam menilai unjuk kerja cache. Tujuan utama organisasi cache adalah menekan prosentase luput, karena setiap terjadi luput, prosesor harus menghabiskan lebih banyak siklus detak untuk mengakses data atau instruksi dari memori utama.
Unjuk kerja cache berkaitan langsung dengan organisasi yang diterapkan. Secara kasar dapat dinyatakan bahwa cache berukuran n yang dipetakan langsung (direct-mapped) memiliki prosentase luput yang sama dengan cache asosiatif-kelompok dua-arah berukuran n/2. Jelas bahwa besarnya kapasitas cache bukanlah ukuran akurat untuk menilai unjuk kerjanya.
Hal lain yang juga perlu diperhatikan dalam membandingkan cache adalah arsitekturnya. Beberapa prosesor menerapkan sistem cache tunggal, yakni dimiliki secara bersama oleh data maupun instruksi. Arsitektur cache jenis ini dikenal sebagai arsitektur Princeton. Prosesor Amd486DX2 merupakan contoh prosesor dengan arsitektur Princeton. Sistem prosesor lain, misalnya P6 (Pentium Pro), menggunakan dua cache, yakni satu cache data dan satu cache instruksi. Prosesor dengan cache ganda seperti ini dikenal sebagai prosesor dengan cache berarsitektur Harvard.
Pemisahan antara cache instruksi dengan cache data menyebabkan hilangnya interferensi antara perujukan data dan perujukan instruksi. Pemisahan cache instruksi dari cache data juga memungkinkan pengambilan data dan instruksi secara bersamaan.
Arsitektur Harvard memiliki dua kelemahan pokok. Jika suatu program memperbarui dirinya sendiri dengan menuliskan instruksi baru, instruksi tersebut akan ditulis dalam cache data. Sebelum instruksi baru itu dapat dieksekusi, kedua cache harus dikosongkan, dan modifikasi yang dilakukan tadi disimpan dulu ke memori utama. Cache instruksi mengambil instruksi hasil modifikasi tersebut dari memori utama. Kelemahan kedua, bila suatu program memerlukan cache instruksi yang lebih besar dan cache data yang lebih kecil, cache berarsitektur Hardvard tidak bisa memenuhi karena alokasinya tidak bisa diubah seperti cache tunggal.
Memori Nyata dan Memori Maya
Sistem operasi yang memberikan fasilitas multitasking, misalnya OS/2 atau Unix, mampu memberikan kesan seolah-olah setiap program mengakses dan mengalokasikan memori sendiri-sendiri tanpa khawatir terjadi tumpang-tindih pemakaian ruang memori. Padahal kenyataannya, setiap byte memori utama hanya memiliki satu alamat saja. Sistem operasi bersama-sama dengan perangkat keras menciptakan dua jenis alamat yakni alamat nyata dan alamat maya. Program menggunakan alamat maya sedangkan pengendali sistem memori memerlukan alamat nyata.
Sistem operasi mengalokasikan memori untuk program dalam unit-unit berukuran tetap yang disebut halaman (page). Satu halaman pada umumnya berukuran 4 KB. Sistem operasi juga menyimpan tabel yang berisi pemetaan halaman maya ke halaman nyata. Setiap kali program mengakses alamat maya, sistem harus melihat tabel translasi alamat maya ke alamat nyata sehingga lokasi memori yang benar dapat diakses.
Sistem pemeriksaan tabel (table look-up) memerlukan waktu operasi yang cukup lama. Oleh karena itu, prosesor menggunakan cache khusus yang disebut sebagai TLB (translation look-aside buffer) untuk menyimpan translasi alamat terbaru. Jadi, hanya bila translasi halaman yang diperlukan tidak tersedia dalam TLB, sistem operasi akan menginterupsi program, memeriksa translasi halaman dalam tabel yang menetap dalam memori (memory resident), mengisikan hasil translasi ke dalam TLB dan mengembalikan kontrol kepada program.
Luput yang terjadi pada TLB memerlukan siklus detak yang lebih banyak daripada luput yang terjadi pada cache. Bila terjadi luput pada TLB maka seluruh alur-pipa (pipeline) harus dikosongkan, register-register harus diselamatkan, rutin pemeriksaan harus dieksekusi, dan register-register harus dipulihkan. Proses ini memerlukan belasan bahkan ratusan siklus detak.
Untuk memeriksa dan menyimpan data dalam cache, baik alamat nyata maupun alamat maya dapat dipakai. Pemilihan organisasi cache mempengaruhi berbagai aspek dalam organisasi sistem komputer dan unjuk-kerja aplikasi.
Cache Alamat Maya
Cache dengan alamat maya memiliki beberapa kelebihan. Pengendali cache tidak perlu menunggu selesainya proses translasi alamat sebelum mulai memeriksa alamat dalam cache sehingga pasokan data dapat lebih cepat diberikan. Karena program juga menggunakan alamat maya, pelaksanaan program yang sama akan membentuk pola pemakaian cache yang sama pula.
Pada cache yang dipetakan ke alamat nyata, sistem operasi bisa saja mengalokasikan halaman nyata yang berbeda untuk pelaksanaan program yang sama. Dengan demikian, tag dari cache untuk alamat-alamat instruksi bisa berbeda pada pelaksanaan program yang sama, bahkan meskipun dilakukan komputasi yang sama. Unjuk-kerja bisa berbeda jauh meskipun program yang dijalankan sama, terutama bila alamat nyata tersebut dipetakan langsung.
Cache Alamat Nyata
Meski cache dengan alamat nyata unjuk-kerjanya bervariasi, cache ini memiliki dua kelebihan. Pertama, jika cache eksternal dirancang untuk prosesor yang memiliki unit pengelola memori internal (on-chip memory management unit), alamat yang dikirimkan oleh prosesor telah merupakan alamat hasil translasi, dan dengan demikian cache dengan alamat nyata adalah satu-satunya pilihan.
Kedua, karena semua alamat adalah untuk ruang alamat-nyata tunggal, maka data dapat ditinggalkan dalam cache saat sistem operasi memindahkan kendali dari satu aplikasi ke aplikasi lain. Hal ini tidak bisa dilakukan pada cache yang menggunakan ruang alamat-maya berbeda untuk tiap-tiap aplikasi. Pada sistem cache dengan alamat-maya, data harus dihapus setiap kali terjadi pemindahan kendali. Bila tidak, aplikasi A misalnya, akan membaca isi alamat 0 aplikasi B, bukan alamat 0nya sendiri.
Karena alasan itulah, cache dengan alamat nyata memiliki unjuk kerja yang lebih baik dalam lingkungan multitasking di mana pemindahan kendali relatif sering terjadi.
Operasi Asinkron
 Gambar 3a
Karena tajamnya perbedaan kecepatan operasi prosesor dengan waktu akses ke memori maka biasanya ditambahkan rangkaian perangkat keras ke dalam prosesor untuk meminimalkan rugi operasi akibat terjadi luput (miss) dalam pengaksesan data/instruksi dalam cache.
Gambar 3a
Karena tajamnya perbedaan kecepatan operasi prosesor dengan waktu akses ke memori maka biasanya ditambahkan rangkaian perangkat keras ke dalam prosesor untuk meminimalkan rugi operasi akibat terjadi luput (miss) dalam pengaksesan data/instruksi dalam cache.
Pada rancangan prosesor yang paling sederhana, jika cache mengisyaratkan terjadinya luput, prosesor berada pada kondisi menunggu. Rangkaian demikian memang sederhana, tetapi memaksa instruksi berikutnya menunggu dieksekusi sampai cache terisi. Pada rancangan yang lebih canggih, prosesor dapat mengeksekusi instruksi-instruksi berikutnya yang tidak bergantung pada isi cache yang ditunggu. Jika terjadi luput lagi sementara luput sebelumnya belum selesai, prosesor akan berhenti sebagai tanda bahwa telah terjadi satu luput. Pada umumnya dapat ditolerir dua atau lebih keadaan luput sebelum prosesor berhenti.
Pada rancangan prosesor paling sederhana, jika terjadi luput, seluruh baris yang berisi nilai yang diperlukan akan diisikan dan diberikan kepada prosesor. Hal ini menjamin bahwa luput berikutnya pada baris yang sama tidak mungkin terjadi saat baris dalam proses dipindahkan.
Metode yang lebih canggih mengisikan baris cache mulai dari kata (word) data yang diminta dan seterusnya sampai ke awal baris. Kata data yang diminta dipasok ke prosesor segera setelah dikirim dari memori, dan sisanya dipindahkan saat prosesor melanjutkan pemrosesan.
Catatan Akhir
Terdapat banyak parameter organisasi cache, masing-masing mempunyai implikasi berbeda terhadap unjuk-kerjanya. Parameter-parameter itu adalah: ukuran cache, ukuran baris, jenis pengalamatan (nyata atau maya) dan derajat ketaksinkronan (yakni, jumah luput yang ditolerir). Perhatian terhadap parameter-perameter tersebut penting dalam mengevaluasi sistem komputer. Hasil uji suatu sistem komputer mungkin berbeda sama sekali bila prosesor yang sama dikombinasikan dengan organisasi cache yang berbeda.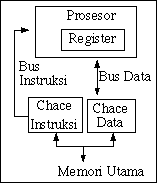 Gambar 3b
Gambar 3b
Daftar Pustaka
- Anonim. 1993. Am486DX/DX2 Hardware Reference Manual. Advanced Micro Devices
- Bacon, David F. 1994. Cache Advantage. Byte, August 1994.
- Halfhill, Tom R. 1995. Intel's P6. Byte, April 1995.
- Hwang, Kai dan Fay_ A. Briggs. 1985. Computer Architecture and Parallel Processing
- Silberschatz, Abraham dan Peter B. Galvin. 1995. Operating System Concept. Massachusetts: Addison-Wesley Publishing Company
- Wilkinson, Barry. 1991. Computer Architecture: Design and Performance. New York: Prentice Hall.
Hari Wibawanto adalah Staf Pengajar Pendidikan Teknik Elektro FPTK IKIP Semarang
[Sajian Utama]
[Sajian Khusus]
[Profil Elektro]
[KOMUNIKASI]
[KENDALI]
[ENERGI]
[ELEKTRONIKA]
[INSTRUMENTASI]
[PII NEWS]
Please send
comments, suggestions, and criticisms about ELEKTRO INDONESIA.
Click here to
send me email.
[Edisi Sebelumnya]
© 1997 ELEKTRO ONLINE and INDOSAT NET.
All Rights Reserved.
{kind=link}